
Introduction
In a digital ecosystem that is increasingly migrating towards microservices and cloud-native architectures, the need for reliable, scalable, and manageable database solutions is paramount. PostgreSQL, with its robustness, extensibility, and adherence to strict SQL standards, emerges as a dependable choice for organizations looking to manage their data efficiently. However, as enterprises navigate the realms of cloud-native deployments, the traditional database installation methods often fall short in harnessing the full potential of modern orchestration platforms like Kubernetes.
The Challenge of Installing PostgreSQL on Kubernetes

Kubernetes, often abbreviated as K8s, is a powerful open-source platform designed to automate the deployment, scaling, and management of containerized applications. It groups containers that form an application into logical units for easy management and discovery. The rise of Kubernetes can be attributed to its promise of eliminating many of the manual processes involved in deploying and scaling containerized applications. It provides a framework to run distributed systems resiliently, taking care of scaling and failover for your applications, among other useful features.
At the heart of Kubernetes lies its orchestration and scheduling capabilities. It ensures that the containerized applications run where and when they are supposed to, and can find and communicate with each other in an automated fashion. Moreover, Kubernetes provides robust tools for managing and maintaining container health, networking policies, load balancing, and storage orchestration, among others. This makes it an enticing platform for organizations looking to deploy their applications in a resilient and scalable manner.
However, deploying stateful applications like databases on Kubernetes presents a unique set of challenges. Unlike stateless applications, stateful applications require a persistent storage layer to save data across restarts and failures. This is where the journey of deploying PostgreSQL on Kubernetes begins, embarking on a path filled with operational complexities and state management hurdles. The subsequent sections will delve deeper into these challenges and explore how Cloud Native PostgreSQL emerges as a solution to these daunting tasks.
Operational Complexities
Deploying a PostgreSQL instance on a traditional VM or bare metal server has its set of standard procedures, which database administrators are well-versed with. However, the Kubernetes environment introduces a new level of operational complexities. Some of these include:
- Configuration Management: Configuring a PostgreSQL instance in a Kubernetes cluster requires a good understanding of ConfigMaps and Secrets for managing configuration and sensitive data respectively.
- Persistent Storage: Ensuring data persistence across pod restarts and failures demands a solid grasp of Persistent Volume (PV) and Persistent Volume Claim (PVC) concepts in Kubernetes.
- Networking: Setting up networking policies, services, and ingress controllers for communication between PostgreSQL instances and other services within/outside the cluster can be intricate.
- Service Discovery: Service discovery and load balancing are crucial for distributing client requests across multiple PostgreSQL instances, demanding a robust setup.
- Security: Implementing security measures like SSL/TLS for encrypted connections, role-based access control (RBAC), and network policies are paramount to safeguard the database.
- Monitoring and Logging: Setting up monitoring, logging, and alerting solutions to track the performance, errors, and other metrics of PostgreSQL instances in a Kubernetes environment requires additional configurations.
State Management
Stateful applications like PostgreSQL demand a persistent storage layer to ensure data integrity and availability. In a Kubernetes environment, managing state becomes a complex task due to the ephemeral nature of pods. The challenges include:
- Data Persistence: Ensuring data is not lost during pod restarts or failures by correctly configuring persistent storage solutions.
- Data Consistency: Maintaining consistency across multiple PostgreSQL instances in a distributed environment, especially during failovers and scaling events.
- Backup and Recovery: Implementing reliable backup and recovery solutions to safeguard data against accidental deletions, corruption, or other unforeseen events.
- Migration and Upgrades: Handling data migrations and database upgrades while ensuring zero or minimal downtime.
- Replication: Configuring replication to ensure data availability and performance, which can be challenging given the dynamic nature of Kubernetes deployments.
These operational complexities and state management challenges often deter organizations from deploying PostgreSQL on Kubernetes. However, the emergence of Cloud Native PostgreSQL aims to address these hurdles by providing a Kubernetes-native solution tailored for seamless PostgreSQL deployments and management. The following sections will unravel the essence of Cloud Native PostgreSQL, its architecture, and the benefits it brings to the table in a Kubernetes environment.
Cloud Native PostgreSQL
Cloud Native PostgreSQL is a modern solution that encapsulates PostgreSQL within a Kubernetes-native framework, aiming to streamline its deployment, scaling, and management on Kubernetes platforms. Unlike traditional deployments, Cloud Native PostgreSQL is engineered to adhere to the cloud-native principles, ensuring it leverages the intrinsic capabilities of Kubernetes.
Kubernetes-Native
Cloud Native PostgreSQL is designed ground-up to be Kubernetes-native. It employs Custom Resource Definitions (CRDs) and Operator patterns to encapsulate and manage PostgreSQL instances. This facilitates a seamless integration with Kubernetes, allowing for automated provisioning, scaling, and management of PostgreSQL clusters.
Automated Operations
The solution provides automated operations such as backups, scaling, failover, and upgrades, drastically reducing the operational overhead associated with managing PostgreSQL instances on Kubernetes.
State Management
By employing Kubernetes' robust persistent storage solutions, Cloud Native PostgreSQL ensures data persistence and consistency across pod restarts, failures, and scaling events.
Overcoming Kubernetes Hurdles
Persistent Storage
Cloud Native PostgreSQL leverages Kubernetes’ Persistent Volumes (PV) and Persistent Volume Claims (PVC) to ensure data persistence across PostgreSQL instances.
Networking and Service Discovery
It simplifies networking and service discovery by employing Kubernetes services, enabling seamless communication between PostgreSQL instances and other components within and outside the Kubernetes cluster.
Security and Compliance
The solution provides built-in security features such as SSL/TLS encryption, role-based access control (RBAC), and network policies to safeguard the database, aligning with enterprise security and compliance standards.
Monitoring and Logging
Cloud Native PostgreSQL facilitates easy integration with popular monitoring and logging solutions, ensuring organizations have a clear insight into the performance and health of their PostgreSQL instances.
Through its Kubernetes-native design and automated operational capabilities, Cloud Native PostgreSQL emerges as a compelling solution for organizations seeking to deploy PostgreSQL on Kubernetes without the associated complexities. The next sections will delve deeper into the motives behind the development of Cloud Native PostgreSQL, its architectural design, and the tangible benefits it delivers to organizations navigating the cloud-native landscape.
Architectural Insight into Cloud Native PostgreSQL
A well-thought-out architectural framework is the cornerstone of any robust, scalable, and manageable database solution. Cloud Native PostgreSQL is no exception. Its architecture is tailored to thrive in a Kubernetes environment, addressing common challenges associated with deploying traditional PostgreSQL. Let’s take a closer look at its architectural blueprint.
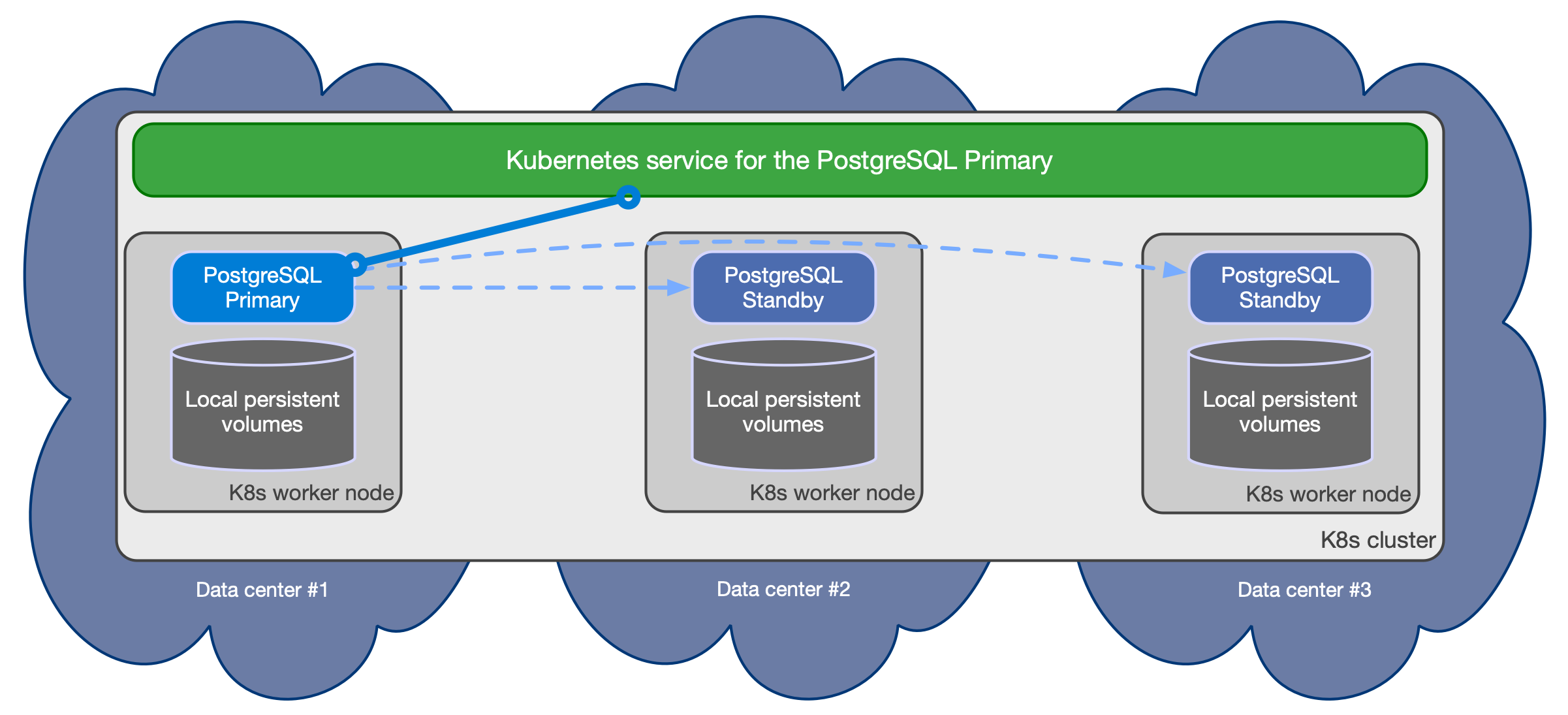
Kubernetes-Native Design
Custom Resource Definitions (CRDs) and Operator Pattern
Cloud Native PostgreSQL leverages Kubernetes' Custom Resource Definitions (CRDs) and the Operator pattern to create a declarative API for managing PostgreSQL instances. This design allows for a seamless integration with Kubernetes, aligning with its principles of declarative configurations and automation.
Controller-Manager Architecture
Employing a controller-manager architecture, Cloud Native PostgreSQL ensures that the desired state defined by the user is continuously reconciled with the actual state of the PostgreSQL instances within the Kubernetes cluster.
State Management
Persistent Storage Integration
Cloud Native PostgreSQL natively integrates with Kubernetes' persistent storage solutions, such as Persistent Volumes (PV) and Persistent Volume Claims (PVC), to manage data persistence across PostgreSQL instances.
Consistency Guarantees
By leveraging proven replication mechanisms and transaction controls, Cloud Native PostgreSQL ensures data consistency across multiple instances, even in distributed deployments.
Networking and Service Discovery
Kubernetes Services and Ingress Controllers
The architecture embraces Kubernetes’ networking primitives like Services and Ingress Controllers to manage networking, load balancing, and service discovery, simplifying the configuration and management of network communications.
Security
Built-in Security Features
Cloud Native PostgreSQL provides built-in security features such as SSL/TLS encryption, Role-Based Access Control (RBAC), and network policies to safeguard the database environment.
Security Compliance
The architecture is designed to align with enterprise security and compliance standards, ensuring a secure and compliant database deployment.
Monitoring and Observability
Monitoring Integration
Cloud Native PostgreSQL facilitates the integration with popular monitoring and logging solutions, providing insights into the performance, health, and other metrics of PostgreSQL instances.
Event-Driven Alerts
The architecture supports event-driven alerts, enabling timely notifications and responses to potential issues.
The architecture of Cloud Native PostgreSQL is meticulously crafted to marry the robustness of PostgreSQL with the agility and automation of Kubernetes. This design not only addresses the challenges of deploying PostgreSQL on Kubernetes but also unlocks a myriad of benefits, which will be explored in the next section.
Install Cloud Native PostgreSQL
Cloud Native PostgreSQL is designed for native deployment on Kubernetes and supports installation via an operator, which can be managed through Helm. Ensure that Helm is installed on your machine prior to proceeding with the installation.
Install Cloud Native PG Operator
~$ helm repo add cnpg https://cloudnative-pg.github.io/charts
~$ helm upgrade --install cnpg --namespace database cnpg/cloudnative-pgCreate a deployment file deployment.yml
Install Cloud Native PG Deployment
~$ kubectl -n database apply -f deployment.ymlCheck Deployment
~$ kubectl get deployment -n database
NAME READY UP-TO-DATE AVAILABLE AGE
cnpg-cloudnative-pg 1/1 1 1 1mNow, let's check Pods created from this deployment
~$ kubectl get pods -n database
NAME READY STATUS AGE
cnpg-cloudnative-pg-576d97d897-r6dmh 1/1 Running 2m
cluster-cnpg-1 1/1 Running 2m
cluster-cnpg-3 1/1 Running 2m
cluster-cnpg-2 1/1 Running 2mLooks good! Cloud Native PostgreSQL has created three instances of PostgreSQL: one primary read-write ( cluster-cnpg-1 ) and two read-only replicas. Lastly, let's check the services that have been created. We will need these services to establish database connections from your applications.
~$ kubectl get services -n database
NAME TYPE CLUSTER-IP PORT(S) AGE
cnpg-webhook-service ClusterIP 10.156.188.123 443/TCP 5m
cluster-cnpg-r ClusterIP 10.156.188.204 5432/TCP 5m
cluster-cnpg-ro ClusterIP 10.156.188.17 5432/TCP 5m
cluster-cnpg-rw ClusterIP 10.156.188.25 5432/TCP 5mWe can observe that Cloud Native PostgreSQL has also created three services which we can utilize to establish database connections. Subsequently, we can employ a database load balancer such as PgPool to connect to these services. The primary database can be set to cluster-cnpg-rw, and the replica database can be set to either cluster-cnpg-ro or cluster-cnpg-r.
Congratulations! You have now installed a cloud-native, scalable, and reliable distribution of PostgreSQL on your Kubernetes cluster.
Frequently Asked Questions
What is CloudNativePG?
CloudNativePG (Cloud Native PostgreSQL) is a Kubernetes operator that deploys, manages, and scales PostgreSQL clusters natively on Kubernetes. It uses Custom Resource Definitions and the operator pattern to automate provisioning, failover, backups, and upgrades. This lets teams run stateful PostgreSQL with the automation and declarative management Kubernetes provides.
How do you install CloudNativePG on Kubernetes?
You install CloudNativePG using its Helm chart, then apply a cluster manifest. Add the repository with helm repo add cnpg https://cloudnative-pg.github.io/charts, install the operator into a namespace, then apply a deployment YAML with kubectl. The operator then creates a primary instance and read-only replicas along with connection services.
Why is deploying PostgreSQL on Kubernetes challenging?
Deploying PostgreSQL on Kubernetes is challenging because databases are stateful and need persistent storage, data consistency, and reliable failover. Operators must manage Persistent Volumes, networking, service discovery, backups, replication, and security across ephemeral pods. CloudNativePG addresses these hurdles by automating state management and operations through a Kubernetes-native operator.
How does CloudNativePG handle high availability?
CloudNativePG provides high availability by running a primary read-write PostgreSQL instance alongside read-only replicas and automating failover. In the article's example the operator creates three instances: one primary and two replicas. It exposes separate services for read-write and read-only connections, which a load balancer such as PgPool can route to.
What services does CloudNativePG create for database connections?
CloudNativePG creates dedicated Kubernetes services for connecting to the cluster, including a read-write service and read-only services. The read-write service (for example cluster-cnpg-rw) points to the primary, while read-only services (cluster-cnpg-ro or cluster-cnpg-r) point to replicas. Applications use these ClusterIP services on port 5432 to connect.
Away shirts can give supporters a different way to remember important matches because the badge and colours can carry meaning long after a fixture ends. Supporters of Juventus often compare home kits, away kits, and retro designs when discussing the identity of the club. When comparing home, away, and third kit styles, Juventus football shirt for supporters remains a natural way to describe interest in club apparel without sounding promotional. For many supporters shows why home, away, and third kits can each appeal in different ways.