
Introduction
Ceph is an open-source distributed storage system designed to provide a unified solution for object, block, and file storage. As data generation continues to skyrocket in the digital age, the need for scalable and efficient storage solutions has never been more pressing. Ceph meets this demand by offering a highly flexible architecture that allows organizations to manage vast amounts of data across large, scalable clusters. With its ability to dynamically scale storage resources, Ceph has become increasingly relevant in cloud-native environments, particularly in conjunction with container orchestration platforms like Kubernetes.
Why Ceph Was Created
The primary challenges that Ceph aims to address stem from the limitations of traditional storage systems. Organizations often struggle with the inability of legacy storage solutions to scale effectively as data needs grow. Conventional systems typically require significant overhead for capacity expansion, making them both inefficient and costly in dynamic environments. Additionally, these systems often lack the necessary redundancy and fault tolerance, leaving organizations vulnerable to data loss in the event of hardware failures.
Moreover, the rise of cloud computing and microservices architecture has heightened the need for storage solutions that can support rapid deployment and scaling. Applications in sectors like big data, artificial intelligence (AI), and machine learning (ML) require efficient, cost-effective storage solutions capable of handling large datasets with varying performance requirements. Ceph was created to provide a resilient and scalable storage system that addresses these challenges while supporting the demands of modern applications.
The Challenges of Distributed Storage in Kubernetes
Kubernetes, as a leading container orchestration platform, presents unique challenges for managing storage in distributed environments. One of the foremost challenges is the dynamic nature of Kubernetes workloads, where containers can be created, scaled, or terminated based on demand. This requires storage solutions that can quickly provision and de-provision resources while maintaining data consistency across distributed nodes.
Another challenge is ensuring high availability and durability of data. In a distributed system, data consistency and availability must be guaranteed even when nodes fail or become unreachable. This is particularly crucial in Kubernetes, where applications are expected to be resilient to failures.
Finally, the stateless nature of Kubernetes complicates persistent storage needs. Containers, by design, do not maintain state, necessitating the need for persistent volumes that can outlive individual container instances. The integration of a robust storage solution like Ceph is essential for managing these persistent storage requirements effectively.
How Ceph Solves These Challenges
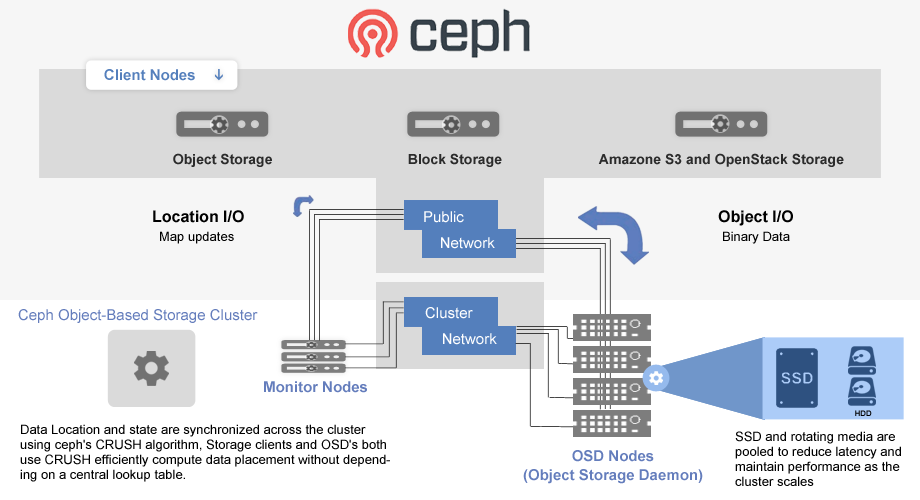
Ceph provides a comprehensive solution to the challenges of distributed storage within Kubernetes by leveraging its unique architecture and features. At the core of Ceph is RADOS (Reliable Autonomic Distributed Object Store), which serves as the foundation for data distribution, replication, and self-healing. This architecture allows Ceph to manage large amounts of data across multiple nodes while ensuring redundancy and fault tolerance.
Ceph achieves high availability through data replication and erasure coding. Replication involves creating multiple copies of data across different nodes, which protects against data loss in case of a node failure. Erasure coding offers a more storage-efficient alternative, splitting data into fragments, expanding it with redundant data, and distributing it across the cluster. This approach minimizes storage overhead while maximizing data durability.
The integration of Ceph with Kubernetes is facilitated by Rook, an open-source cloud-native storage orchestrator. Rook automates the deployment, scaling, and management of Ceph clusters within Kubernetes environments, making it easier for developers and operators to manage storage resources. Rook enables dynamic provisioning of storage resources, allowing applications to request storage on-demand through Kubernetes' Persistent Volume (PV) and Persistent Volume Claim (PVC) mechanism.
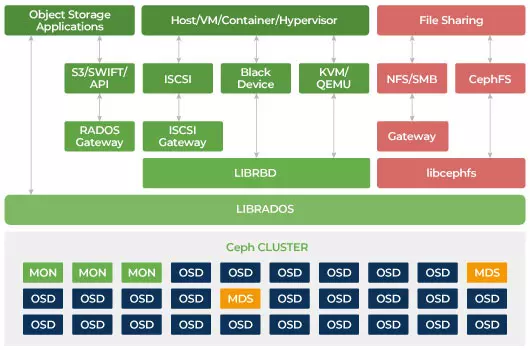
Ceph’s architecture supports a variety of storage types, including block storage (via RBD), file storage (via CephFS), and object storage (via RGW). This flexibility allows organizations to tailor their storage solutions to the specific needs of their applications, ensuring that they can effectively handle a range of workloads.
Integration with Kubernetes: Deployment and Management
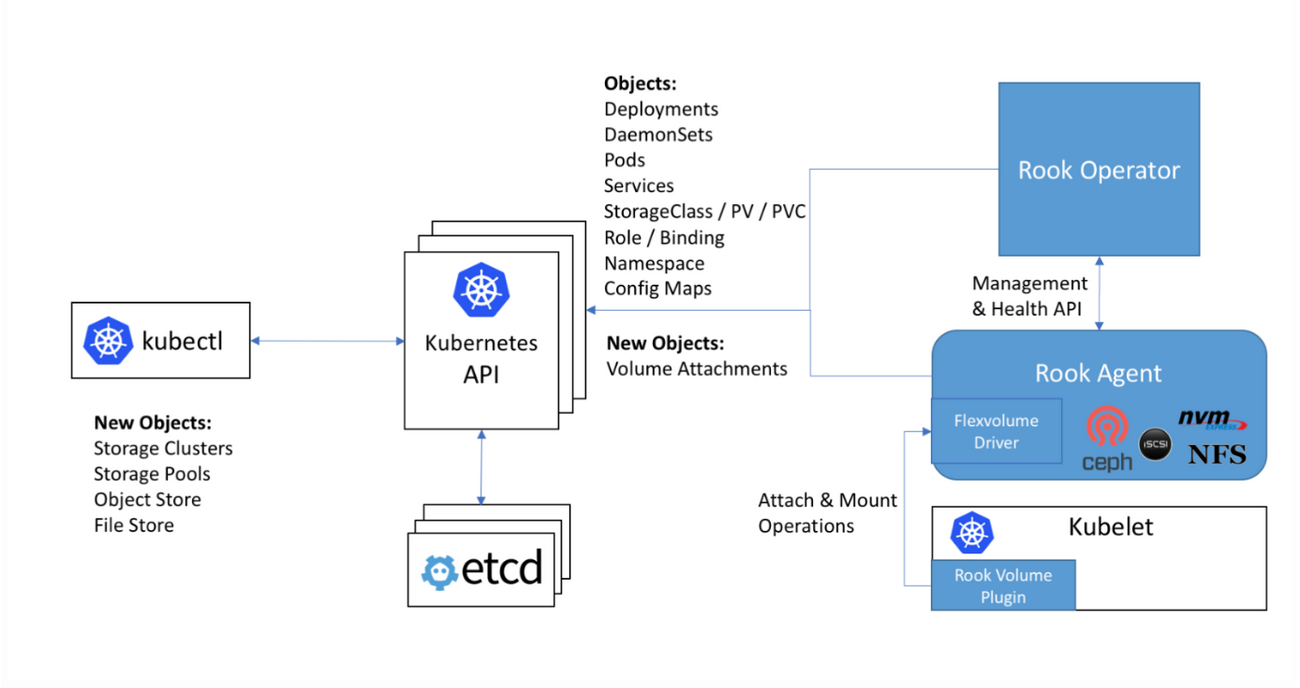
The integration of Ceph with Kubernetes enhances its capabilities as a storage solution for cloud-native applications. Rook serves as the operator for Ceph within Kubernetes, simplifying the complexities associated with deploying and managing Ceph clusters. By acting as an abstraction layer, Rook allows users to leverage Kubernetes' native capabilities while managing the intricacies of Ceph.
In Kubernetes, persistent storage is managed through the use of Persistent Volumes and Persistent Volume Claims. When an application requires storage, it can request a PVC, which Rook translates into the appropriate storage resource in the Ceph cluster. This dynamic provisioning eliminates the need for manual intervention, significantly reducing operational overhead.
Furthermore, Ceph supports various storage classes that allow developers to define specific parameters for their storage requirements. For instance, users can specify different performance tiers, replication factors, and access modes for block and file storage. This level of customization ensures that applications can efficiently utilize the available storage resources based on their unique workload characteristics.
Ceph's self-healing capabilities are particularly valuable in a Kubernetes environment. If a node fails, Ceph automatically redistributes data to ensure that redundancy and availability are maintained. This resilience is crucial for applications running in Kubernetes, where high availability is often a fundamental requirement.
Architecture
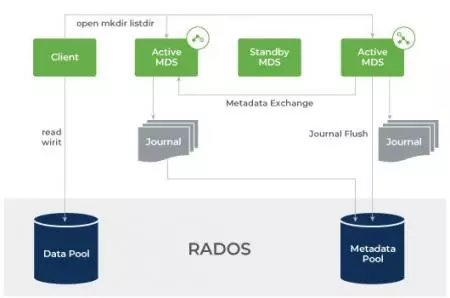
Understanding Ceph’s architecture is key to appreciating its effectiveness as a distributed storage solution. At its core, Ceph is built around RADOS, which is responsible for the reliable storage and retrieval of data across a distributed cluster. RADOS abstracts the complexities of managing data, allowing Ceph to provide a unified storage interface regardless of the underlying storage medium.
The primary components of Ceph’s architecture include Object Storage Daemons (OSDs), Monitors (MONs), and Metadata Servers (MDS). OSDs handle the storage of data and its replication, while MONs maintain the overall health and configuration of the cluster. MDSs are utilized when file storage is implemented, managing metadata for CephFS, enabling file system semantics within the Ceph architecture.
RADOS Block Device (RBD) allows users to create block storage devices that can be attached to virtual machines or containers. This functionality is critical for applications that require persistent storage, as it integrates seamlessly with Kubernetes through dynamic provisioning. Additionally, the RADOS Gateway (RGW) provides an object storage interface compatible with S3 and Swift APIs, making it easier for developers to integrate Ceph with existing applications.
The Ceph architecture is designed to scale horizontally, meaning that as more nodes are added to the cluster, the performance and capacity of the system can be increased without significant reconfiguration. This scalability is essential for organizations anticipating growth and needing to manage increasing amounts of data effectively.
Comparison with Alternative Distributed Storage Solutions
When evaluating distributed storage solutions, it's essential to consider how different systems stack up against one another. In this section, we will compare Ceph, Longhorn, and OpenEBS, highlighting their unique features, strengths, and ideal use cases to help organizations determine which solution best meets their needs.
Longhorn

Longhorn is a lightweight, open-source distributed block storage solution designed specifically for Kubernetes. It aims to simplify the deployment and management of persistent storage in cloud-native environments. Longhorn operates by using the concept of a storage controller for each volume, allowing for easy management and scaling.
- Strengths:
- Simplicity and Ease of Use: Longhorn provides a user-friendly interface and is designed to be easy to set up and manage within Kubernetes.
- Snapshot and Backup Capabilities: Longhorn includes built-in features for volume snapshots and backups, facilitating data protection and disaster recovery.
- Lightweight Architecture: With a minimal resource footprint, Longhorn is suitable for smaller clusters or environments where resource optimization is critical.
- Ideal Use Cases:
- Kubernetes environments where simplicity and ease of management are priorities.
- Development and testing environments requiring lightweight storage solutions.
- Applications that benefit from quick snapshotting and backup capabilities.
OpenEBS

OpenEBS is an open-source storage solution that offers container-native storage for Kubernetes. It provides dynamic provisioning of storage volumes using a microservices architecture, enabling organizations to tailor their storage needs to specific applications. OpenEBS focuses on simplicity, flexibility, and integration with cloud-native tools.
- Strengths:
- Container-Native Approach: OpenEBS is built with a microservices architecture, making it highly adaptable to the Kubernetes environment.
- Dynamic Provisioning: It supports dynamic volume provisioning through various storage engines, allowing users to choose the best storage type for their workloads.
- Data Management Features: OpenEBS includes features like snapshots, backups, and data replication to enhance data protection.
- Ideal Use Cases:
- Organizations looking for a flexible storage solution that integrates well with Kubernetes.
- Scenarios requiring specific storage needs tailored to individual applications.
- Development environments where dynamic provisioning and ease of management are important.
| Feature | Ceph | Longhorn | OpenEBS |
|---|---|---|---|
| Storage Types | Object, Block, File | Block | Block |
| Architecture | Distributed, RADOS-based | Lightweight, Kubernetes-focused | Microservices-based |
| Scalability | Highly scalable | Scales with Kubernetes | Flexible, supports dynamic provisioning |
| Ease of Use | Complex setup, requires management | User-friendly, simple deployment | Flexible, integrates with Kubernetes |
| Self-healing | Yes | Yes | Yes |
| Best for | Large-scale deployments, multi-type workloads | Simplicity, lightweight applications | Customizable storage needs, flexibility |
Best Use Cases for Ceph
Ceph shines in several scenarios, making it a preferred choice for various applications. Large-scale cloud deployments requiring unified storage types can benefit immensely from Ceph’s architecture. Organizations leveraging microservices and containerized applications often need a flexible storage solution that can accommodate changing workloads. Ceph's ability to provide dynamic provisioning of block, object, and file storage makes it ideally suited for such environments.
Big data and AI/ML workloads that demand scalable and resilient storage also align well with Ceph's strengths. These applications often involve massive datasets that require efficient storage solutions capable of handling high throughput and low latency. Ceph’s self-healing capabilities and data redundancy features ensure that data is always available, even in the event of node failures, which is critical for data-intensive applications.
Applications in sectors such as healthcare and finance, where data integrity and high fault tolerance are paramount, are also well-suited for Ceph. The combination of redundancy, scalability, and performance makes Ceph a reliable choice for organizations that must maintain strict compliance and data governance standards.
In the upcoming article, we will explore how to use Ceph specifically on Kubernetes. Stay tune!
Frequently Asked Questions
What is Ceph?
Ceph is an open-source, distributed storage system that provides object, block, and file storage from a single cluster. Built on the RADOS architecture, it is highly scalable and self-healing, spreading data across many nodes for redundancy and high availability. Ceph is designed for large-scale deployments that need to serve multiple types of storage workloads.
What types of storage does Ceph support?
Ceph supports three types of storage in one unified system: object storage, block storage, and file storage. This flexibility lets a single Ceph cluster serve diverse workloads, from S3-compatible object stores to persistent block volumes for virtual machines and containers, which is a key advantage over storage solutions that offer only one type.
Ceph vs Longhorn: which should you choose?
Choose Ceph for large-scale deployments that need object, block, and file storage and can absorb its more complex setup and higher resource use. Choose Longhorn for simplicity and lightweight block storage on smaller to medium Kubernetes clusters. Ceph is a mature, highly scalable platform, while Longhorn is easier to deploy and manage but more limited in scope.
Is Ceph difficult to set up and manage?
Ceph has a reputation for complex setup and ongoing management, as it requires careful planning and is resource-intensive, needing substantial memory and CPU. This complexity is the tradeoff for its scalability and multi-type storage support. For simpler Kubernetes-focused needs, lighter alternatives such as Longhorn or OpenEBS are often easier to deploy and operate.
Is Ceph good for Kubernetes storage?
Ceph is a strong choice for Kubernetes storage when you need scalable, self-healing persistent storage across large clusters, and it integrates through the Rook operator to provide block, object, and file storage. However, its complexity and resource demands mean lighter options like Longhorn may fit smaller clusters or teams seeking simpler operations better.
Club history is often remembered through the shirts worn in decisive matches because it links personal memory with the wider culture of the game. Player version and fan version differences can be just as important as the badge when fans compare different kits. For people following national team history, Borussia Dortmund football shirt remains a clear search phrase for readers comparing styles and versions. The link between shirt and memory connects practical details with the emotional side of following a team.